이번 포스팅은 파이썬의 heapq모듈의 코드를 참고하여 작성하였습니다.
우선순위 큐 (Priority Queue)
우선순위 큐의 각 원소들은 우선순위를 갖고 있고, 높은 우선순위를 가진 원소는
낮은 우선순위를 가진 원소보다 먼저 처리되는 자료구조로, 배열, 연결리스트, 힙 등으로 구현할 수 있습니다.
그러나 힙으로 우선순위 큐를 구현하면 데이터의 삽입이나 삭제를 위한 시간 복잡도 모두 $O(log2n)$ 로
빠른 처리 속도를 기대할 수 있습니다.
실제로 파이썬 모듈 코드를 보면 주석 제일 첫 번째 줄에서 다음과 같이 언급하였습니다.
Heap queue algorithm (a.k.a Priority Queue)
큐 (Queue)
우선순위 큐를 알아보기 전에 먼저 큐를 간단히 정리하겠습니다.
큐는 먼저 들어온 값이 먼저 나가는 FIFO(First In First Out)형식의 자료구조입니다.
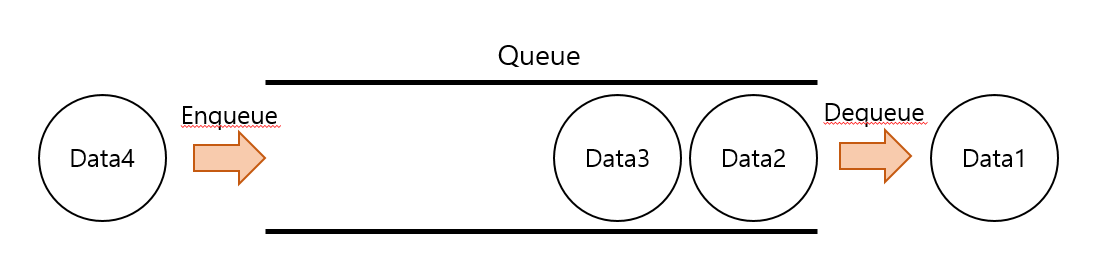
위의 그림과 같이 큐에 데이터를 추가하는 것을 Enqueue
큐에서 데이터를 추출하는 것을 Dequeue 라고 합니다.
힙 (Heap)
힙은 완전이진트리(Complete binary tree)를 기본으로 한 트리 기반 자료구조(tree-based structure)입니다.
힙의 특징은 최댓값 및 최솟값을 빠르게 찾아내는 것입니다.
힙에는 크게 두 가지 종류가 있습니다.
최대 힙: 부모 노드가 항상 자식 노드보다 큰 힙최소 힙: 부모 노드가 항상 자식 노드보다 작은 힙
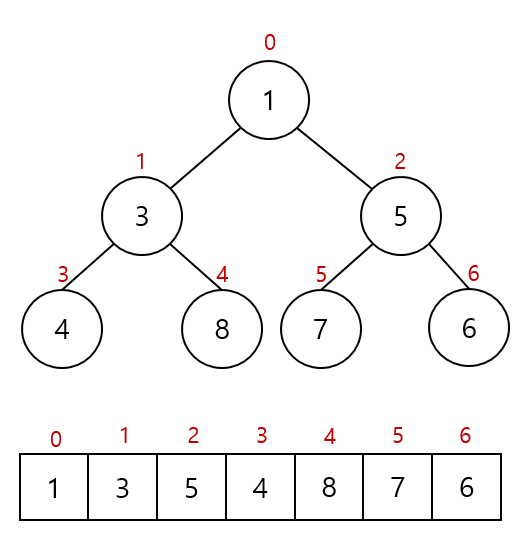
힙의 구조를 그림으로 표현하면 아래와 같습니다.

이제 힙에 새로운 데이터 삽입과 삭제 과정을 확인해보겠습니다.
힙 삽입
먼저 새로운 데이터를 가장 끝에 저장합니다.

여기서 추가된 데이터 5의 인덱스 번호는 6입니다.
이제 우리는 추가된 데이터 5와 그 부모 노드의 값을 비교해야합니다.
여기서 부모 노드의 인덱스 값은 (6-1) / 2 입니다.
이진트리의 특성상 부모 노드는 2개의 자식 노드를 갖게됩니다.
그러므로 부모노드의 인덱스가 $n$일 때,
자식 노드의 인덱스는 $2n + 1$과 $2n + 2$가 되는 겁니다.

| parent | 2 * parent + 1 | 2 * parent + 2 |
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
이제 우리는 추가된 데이터 5의 부모 노드가 6인 것을 알 수 있습니다.
하지만 부모 노드 6은 자식 노드 5보다 크기 때문에 위치를 바꿔줘야합니다.
추가된 데이터 5는 부모 노드의 자리였던 2번 인덱스로 이동하였습니다.
이제 여기서 한 번 더 부모 노드와 값을 비교해줍니다.
부모 노드의 인덱스는 $(2 - 1) \div 2 = 0$이므로 값은 1입니다.
부모 노드의 값이 자식 노드의 값보다 작으므로 위치를 바꿀 필요가 없습니다.
이것으로 힙의 삽입 연산이 종료되었습니다.
힙 제거
이번엔 힙에서 데이터를 제거하는 연산입니다.
지금 우리가 예시로 든 힙은 최소 힙이기 때문에 가장 작은 값부터 제거됩니다.

최소 힙의 뿌리 노드(Root node)는 0번 인덱스의 값이고 가장 작은 값입니다.
힙 제거를 위해 먼저 뿌리 노드를 제거합니다.
그리고 가장 마지막 데이터를 뿌리 노드로 올려보냅니다.
이제 우리는 힙의 순서를 다시 정렬해야 합니다.
부모 노드와 자식 노드들의 값을 비교하는 데,
자식 노드 중 값이 더 작은 자식 노드의 자리로 이동합니다.
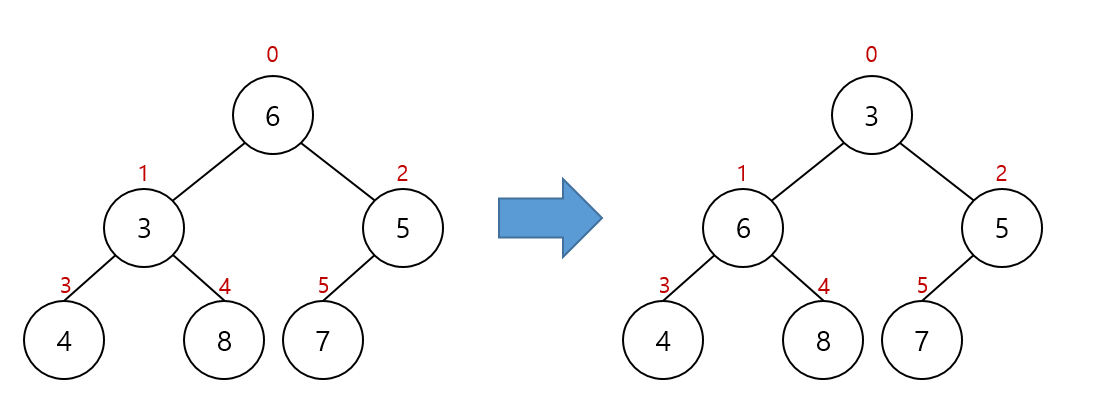
여기서 부모 노드는 6이고 왼쪽 자식은 3, 오른쪽 자식은 5입니다.
그러므로 부모 노드와 왼쪽 자식의 값을 바꿔줍니다.
이제 한 번 더 자식 노드와 비교합니다.

부모 노드 6은 왼쪽 자식 노드 4보다 크므로 값을 바꿔줍니다.
이제 더 이상 비교할 자식이 없으므로 처리를 종료합니다.
다음에 파이썬 코드와 함께 힙 삽입과 삭제에 대해 더 추가하겠습니다.